install.packages(c("dplyr", "gutenbergr", "stringr", "tidytext", "tidyr", "stopwords", "wordcloud", "rsample", "glmnet", "forcats", "broom", "igraph", "ggraph", "kableExtra", "yardstick")) Introduction to Textmining in R
This post demonstrates how various R packages can be used for text mining in R. In particular, we start with common text transformations, perform various data explorations with term frequency (tf) and inverse document frequency (idf) and build a supervised classifiaction model that learns the difference between texts of different authors.
The content of this tutorial is based on the excellent book “Textmining with R (2019)” from Julia Silge and David Robinson and the blog post “Text classification with tidy data principles (2018)” from Julia Silges.
Installation of R packages
If you like to install all packages at once, use the code below.
Data import
We can access the full texts of various books from “Project Gutenberg” via the gutenbergr package. We can look up certain authors or titles with a regular expression using the stringr package. All functions in stringr start with str_and take a vector of strings as the first argument. To learn more about stringr, visit the stringr documentation.
library(gutenbergr)
library(stringr)
doyle <- gutenberg_works(str_detect(author, "Doyle"))library(kableExtra)
knitr::kable(head(doyle, 4)) |>
kable_styling(bootstrap_options = c("striped", "hover", "condensed", "responsive"))| gutenberg_id | title | author | gutenberg_author_id | language | gutenberg_bookshelf | rights | has_text |
|---|---|---|---|---|---|---|---|
| 108 | The Return of Sherlock Holmes | Doyle, Arthur Conan | 69 | en | Detective Fiction | Public domain in the USA. | TRUE |
| 126 | The Poison Belt | Doyle, Arthur Conan | 69 | en | Science Fiction | Public domain in the USA. | TRUE |
| 139 | The Lost World | Doyle, Arthur Conan | 69 | en | Science Fiction | Public domain in the USA. | TRUE |
| 244 | A Study in Scarlet | Doyle, Arthur Conan | 69 | en | Detective Fiction | Public domain in the USA. | TRUE |
We obtain “Relativity: The Special and General Theory” by Albert Einstein (gutenberg_id: 30155) and “Experiments with Alternate Currents of High Potential and High Frequency” by Nikola Tesla (gutenberg_id: 13476) from gutenberg and add the column “author” to the result.
books <- gutenberg_download(c(30155, 13476), meta_fields = "author")Furthermore, we transfrom the data to a tibble (tibbles are a modern take on data frames), add the row number with the column name document to the tibble and drop the column gutenberg_id. We will use the information in column document to train a model that can take an individual line (row) and give us a probability that the text in this particular line comes from a certain author.
library(dplyr)
books <- as_tibble(books) |>
mutate(document = row_number()) |>
select(-gutenberg_id)kable(head(books, 8)) |>
kable_styling(bootstrap_options = c("striped", "hover", "condensed", "responsive"))| text | author | document |
|---|---|---|
| EXPERIMENTS WITH ALTERNATE CURRENTS OF HIGH POTENTIAL AND HIGH FREQUENCY | Tesla, Nikola | 1 |
| Tesla, Nikola | 2 | |
| A Lecture Delivered before the Institution of Electrical Engineers, London | Tesla, Nikola | 3 |
| Tesla, Nikola | 4 | |
| by | Tesla, Nikola | 5 |
| Tesla, Nikola | 6 | |
| NIKOLA TESLA | Tesla, Nikola | 7 |
| Tesla, Nikola | 8 |
Data transformation
Tokenization
First of all, we need to both break the text into individual tokens (a process called tokenization) and transform it to a tidy data structure (i.e. each variable must have its own column, each observation must have its own row and each value must have its own cell). To do this, we use tidytext’s unnest_tokens() function. We also remove the rarest words in that step, keeping only words in our dataset that occur more than 10 times.
library(tidytext)
tidy_books <- books |>
unnest_tokens(word, text) |>
group_by(word) |>
filter(n() > 10) |>
ungroup()kable(head(tidy_books, 8)) |>
kable_styling(bootstrap_options = c("striped", "hover", "condensed", "responsive"))| author | document | word |
|---|---|---|
| Tesla, Nikola | 1 | experiments |
| Tesla, Nikola | 1 | with |
| Tesla, Nikola | 1 | alternate |
| Tesla, Nikola | 1 | currents |
| Tesla, Nikola | 1 | of |
| Tesla, Nikola | 1 | high |
| Tesla, Nikola | 1 | potential |
| Tesla, Nikola | 1 | and |
Stop words
Now that the data is in a tidy “one-word-per-row” format, we can manipulate it with packages like dplyr. Often in text analysis, we will want to remove stop words: Stop words are words that are not useful for an analysis, typically extremely common words such as “the”, “of”, “to”, and so forth. We can remove stop words in our data by using the stop words provided in the package stopwords with an anti_join() from the package dplyr.
library(stopwords)
library(tibble)
stopword <- as_tibble(stopwords::stopwords("en"))
stopword <- rename(stopword, word=value)
tb <- anti_join(tidy_books, stopword, by = 'word')kable(head(tb, 8)) |>
kable_styling(bootstrap_options = c("striped", "hover", "condensed", "responsive"))| author | document | word |
|---|---|---|
| Tesla, Nikola | 1 | experiments |
| Tesla, Nikola | 1 | alternate |
| Tesla, Nikola | 1 | currents |
| Tesla, Nikola | 1 | high |
| Tesla, Nikola | 1 | potential |
| Tesla, Nikola | 1 | high |
| Tesla, Nikola | 1 | frequency |
| Tesla, Nikola | 3 | lecture |
The tidy data structure allows different types of exploratory data analysis (EDA), which we turn to next.
Exploratory data analysis
Term frequency (tf)
An important question in text mining is how to quantify what a document is about. One measure of how important a word may be is its term frequency (tf), i.e. how frequently a word occurs in a document.
We can start by using dplyr to explore the most commonly used words.
word_count <- count(tb, word, sort = TRUE)kable(head(word_count, 5)) |>
kable_styling(bootstrap_options = c("striped", "hover", "condensed", "responsive"))| word | n |
|---|---|
| one | 239 |
| body | 230 |
| may | 224 |
| can | 194 |
| relativity | 193 |
Term frequency by author:
author_count <- tb |>
count(author, word, sort = TRUE)kable(head(author_count, 10)) |>
kable_styling(bootstrap_options = c("striped", "hover", "condensed", "responsive"))| author | word | n |
|---|---|---|
| Einstein, Albert | relativity | 193 |
| Tesla, Nikola | may | 184 |
| Einstein, Albert | theory | 181 |
| Tesla, Nikola | bulb | 171 |
| Tesla, Nikola | coil | 166 |
| Tesla, Nikola | high | 166 |
| Einstein, Albert | body | 156 |
| Tesla, Nikola | one | 156 |
| Einstein, Albert | reference | 150 |
| Tesla, Nikola | tube | 147 |
Plot terms with a frequency greater than 100:
library(ggplot2)
tb |>
count(author, word, sort = TRUE) |>
filter(n > 100) |>
mutate(word = reorder(word, n)) |>
ggplot(aes(word, n)) +
geom_col(aes(fill=author)) +
xlab(NULL) +
scale_y_continuous(expand = c(0, 0)) +
coord_flip() +
theme_classic(base_size = 12) +
labs(fill= "Author", title="Word frequency", subtitle="n > 100")+
theme(plot.title = element_text(lineheight=.8, face="bold")) +
scale_fill_brewer() 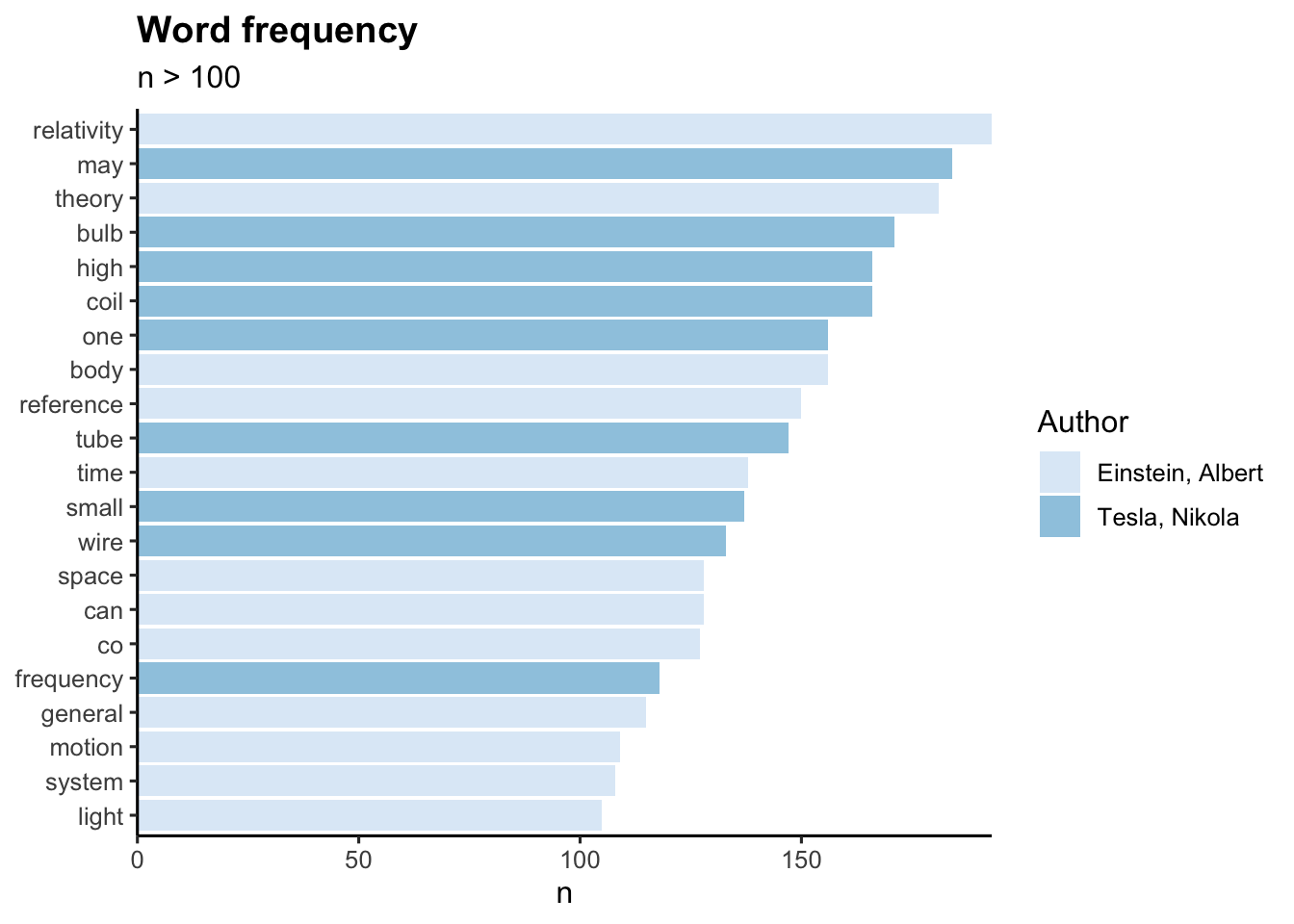
Plot top 20 terms by author:
tb |>
count(author, word, sort = TRUE) |>
group_by(author) |>
top_n(20) |>
ungroup() |>
ggplot(aes(reorder_within(word, n, author), n,
fill = author)) +
geom_col(alpha = 0.8, show.legend = FALSE) +
scale_x_reordered() +
coord_flip() +
facet_wrap(~author, scales = "free") +
scale_y_continuous(expand = c(0, 0)) +
theme_classic(base_size = 12) +
labs(fill= "Author",
title="Most frequent words",
subtitle="Top 20 words by book",
x= NULL,
y= "Word Count")+
theme(plot.title = element_text(lineheight=.8, face="bold")) +
scale_fill_brewer() 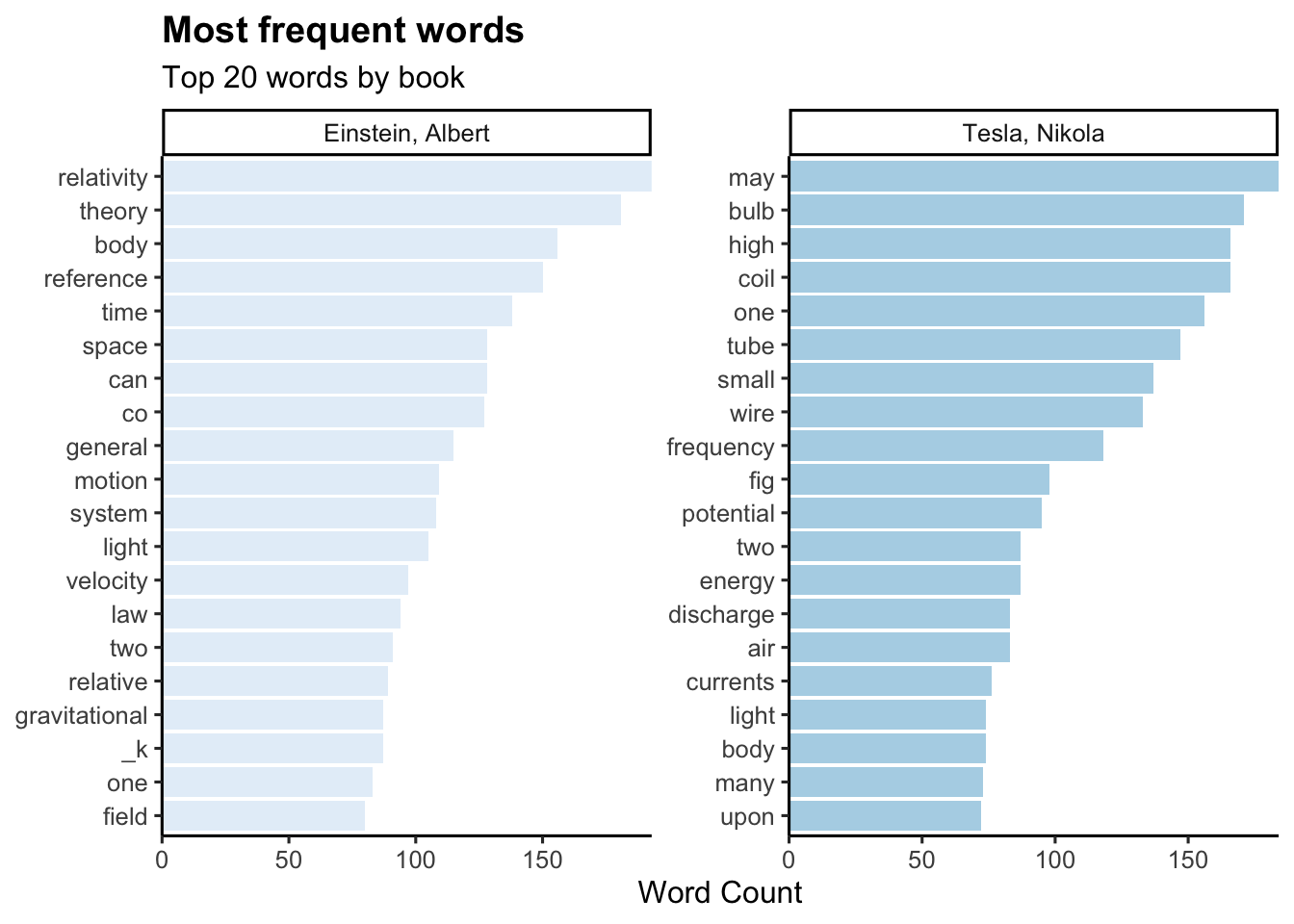
You may notice expressions like “_k”, “co” in the Einstein text and “fig” in the Tesla text. Let’s remove these and other less meaningful words with a custom list of stop words and use anti_join() to remove them.
newstopwords <- tibble(word = c("eq", "co", "rc", "ac", "ak", "bn", "fig", "file", "cg", "cb", "cm", "ab", "_k", "_k_", "_x"))
tb <- anti_join(tb, newstopwords, by = "word")Now we plot the data again without the new stopwords:
tb |>
count(author, word, sort = TRUE) |>
group_by(author) |>
top_n(20) |>
ungroup() |>
ggplot(aes(reorder_within(word, n, author), n,
fill = author)) +
geom_col(alpha = 0.8, show.legend = FALSE) +
scale_x_reordered() +
coord_flip() +
facet_wrap(~author, scales = "free") +
scale_y_continuous(expand = c(0, 0)) +
theme_classic(base_size = 12) +
labs(fill= "Author",
title="Most frequent words after removing stop words",
subtitle="Top 20 words by book",
x= NULL,
y= "Word Count")+
theme(plot.title = element_text(lineheight=.8, face="bold")) +
scale_fill_brewer() 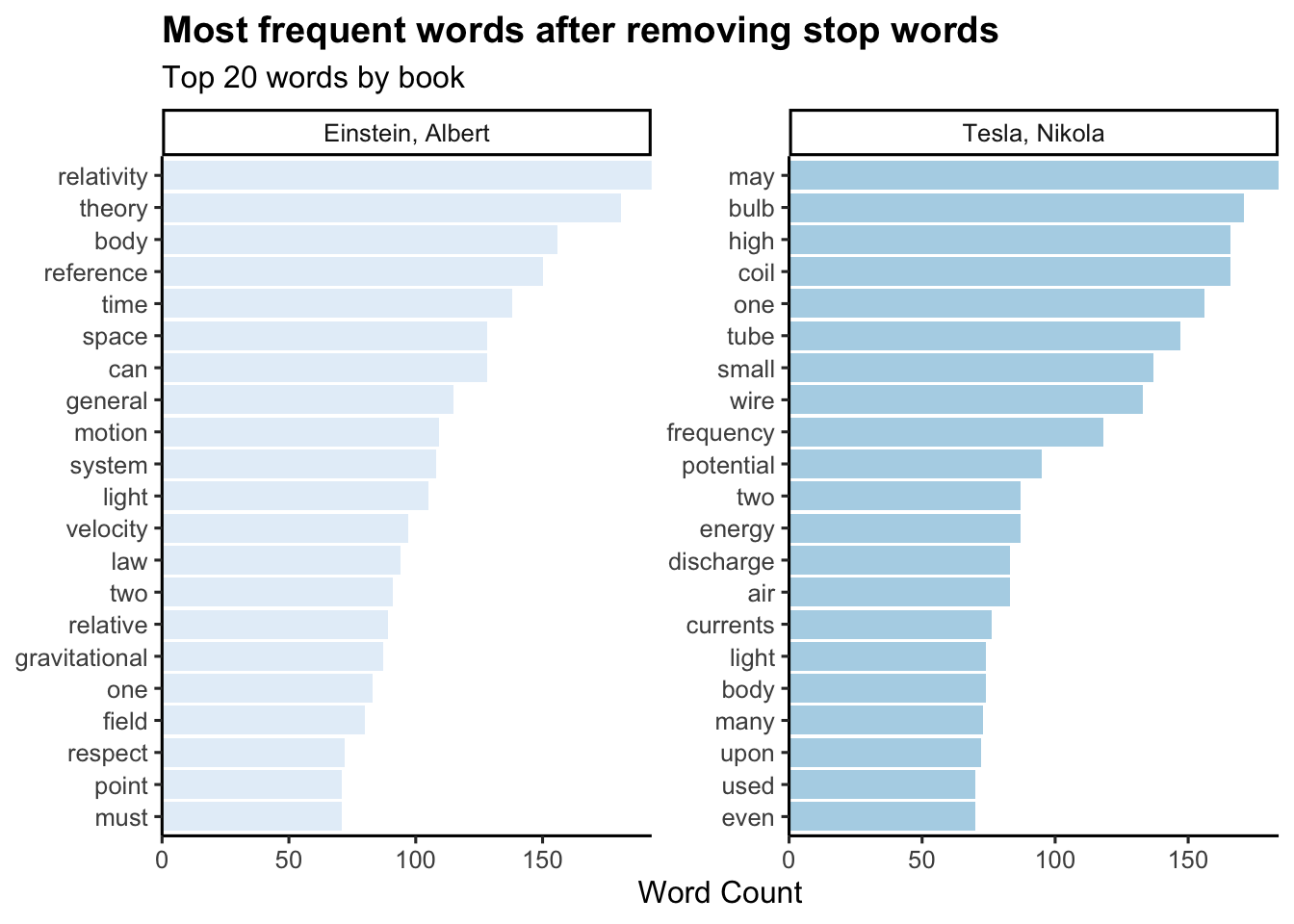
You also may want to visualize the most frequent terms as a simple word cloud:
library(wordcloud)
tb |>
count(word) |>
with(wordcloud(word, n, max.words = 15))
Term frequency and inverse document frequency (tf-idf)
Term frequency is a useful measure to determine how frequently a word occurs in a document. There are words in a document, however, that occur many times but may not be important.
Another approach is to look at a term’s inverse document frequency (idf), which decreases the weight for commonly used words and increases the weight for words that are not used very much in a collection of documents. This can be combined with term frequency to calculate a term’s tf-idf (the two quantities multiplied together), the frequency of a term adjusted for how rarely it is used.
The inverse document frequency for any given term is defined as:
\[idf(\text{term}) = \ln{\left(\frac{n_{\text{documents}}}{n_{\text{documents containing term}}}\right)}\]
Hence, term frequency and inverse document frequency allows us to find words that are characteristic for one document within a collection of documents. The tidytext package uses an implementation of tf-idf consistent with tidy data principles that enables us to see how different words are important in documents within a collection or corpus of documents.
library(forcats)
plot_tb <- tb |>
count(author, word, sort = TRUE) |>
bind_tf_idf(word, author, n) |>
mutate(word = fct_reorder(word, tf_idf)) |>
mutate(author = factor(author,
levels = c("Tesla, Nikola",
"Einstein, Albert")))
plot_tb |>
group_by(author) |>
top_n(15, tf_idf) |>
ungroup() |>
mutate(word = reorder(word, tf_idf)) |>
ggplot(aes(word, tf_idf, fill = author)) +
scale_y_continuous(expand = c(0, 0)) +
geom_col(show.legend = FALSE) +
labs(x = NULL, y = "tf-idf") +
facet_wrap(~author, ncol = 2, scales = "free") +
coord_flip() +
theme_classic(base_size = 12) +
labs(fill= "Author",
title="Term frequency and inverse document frequency (tf-idf)",
subtitle="Top 20 words by book",
x= NULL,
y= "tf-idf") +
theme(plot.title = element_text(lineheight=.8, face="bold")) +
scale_fill_brewer() 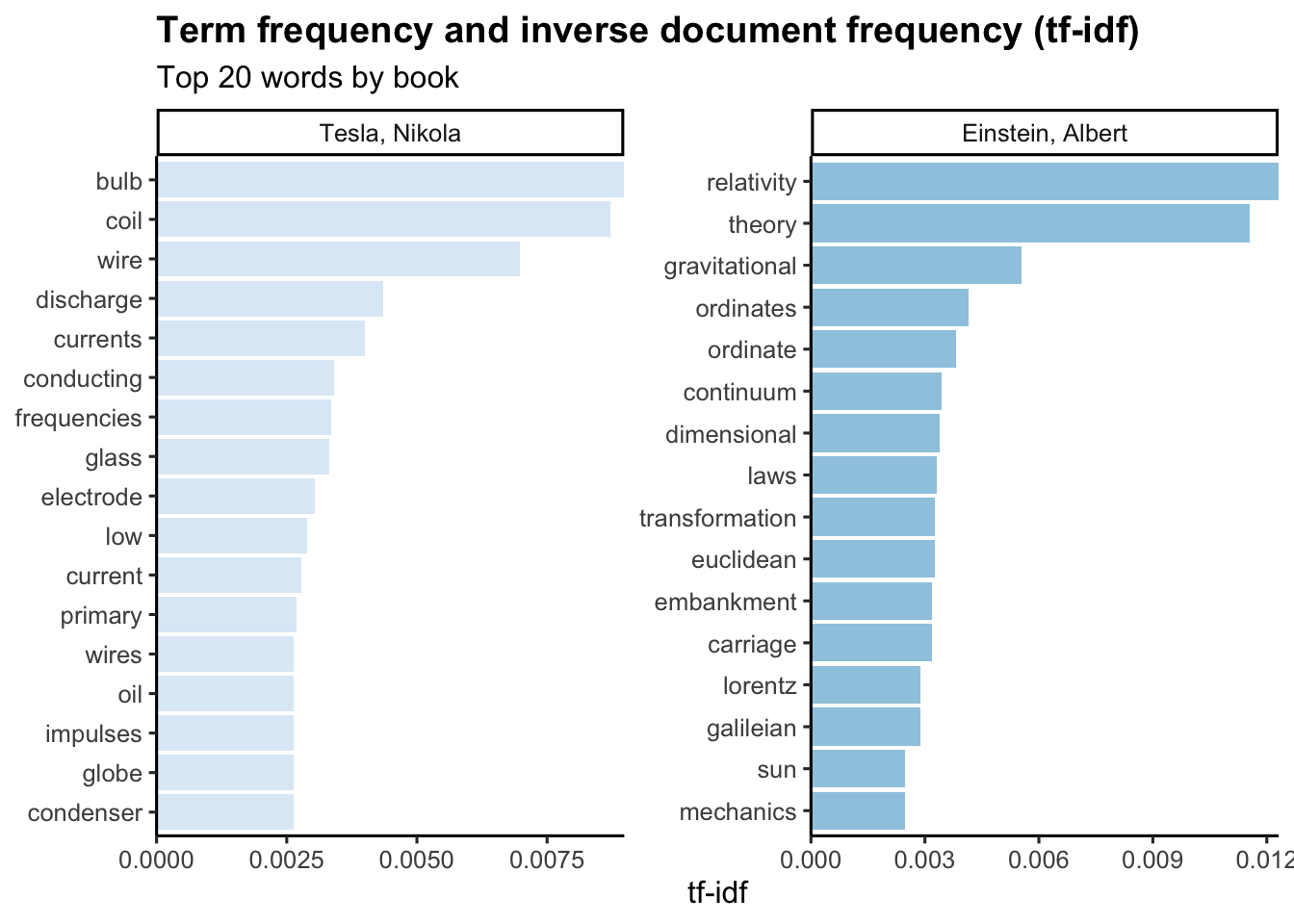
In particular, the bind_tf_idf function in the tidytext package takes a tidy text dataset as input with one row per token (term), per document. One column (word here) contains the terms/tokens, one column contains the documents (authors in this case), and the last necessary column contains the counts, how many times each document contains each term (n in this example).
tf_idf <- tb |>
count(author, word, sort = TRUE) |>
bind_tf_idf(word, author, n)kable(head(tf_idf, 10)) |>
kable_styling(bootstrap_options = c("striped", "hover", "condensed", "responsive"))| author | word | n | tf | idf | tf_idf |
|---|---|---|---|---|---|
| Einstein, Albert | relativity | 193 | 0.0177618 | 0.6931472 | 0.0123116 |
| Tesla, Nikola | may | 184 | 0.0139436 | 0.0000000 | 0.0000000 |
| Einstein, Albert | theory | 181 | 0.0166575 | 0.6931472 | 0.0115461 |
| Tesla, Nikola | bulb | 171 | 0.0129585 | 0.6931472 | 0.0089821 |
| Tesla, Nikola | coil | 166 | 0.0125796 | 0.6931472 | 0.0087195 |
| Tesla, Nikola | high | 166 | 0.0125796 | 0.0000000 | 0.0000000 |
| Einstein, Albert | body | 156 | 0.0143567 | 0.0000000 | 0.0000000 |
| Tesla, Nikola | one | 156 | 0.0118218 | 0.0000000 | 0.0000000 |
| Einstein, Albert | reference | 150 | 0.0138045 | 0.0000000 | 0.0000000 |
| Tesla, Nikola | tube | 147 | 0.0111397 | 0.0000000 | 0.0000000 |
Notice that idf and thus tf-idf are zero for extremely common words (like “may”). These are all words that appear in both documents, so the idf term (which will then be the natural log of 1) is zero. The inverse document frequency (and thus tf-idf) is very low (near zero) for words that occur in many of the documents in a collection; this is how this approach decreases the weight for common words. The inverse document frequency will be a higher number for words that occur in fewer of the documents in the collection.
Tokenizing by n-gram
We’ve been using the unnest_tokens function to tokenize by word, or sometimes by sentence, which is useful for the kinds of frequency analyses we’ve been doing so far. But we can also use the function to tokenize into consecutive sequences of words, called n-grams. By seeing how often word X is followed by word Y, we can then build a model of the relationships between them.
einstein_bigrams <- books |>
filter(author == "Einstein, Albert") |>
unnest_tokens(bigram, text, token = "ngrams", n = 2)kable(head(einstein_bigrams, 10)) |>
kable_styling(bootstrap_options = c("striped", "hover", "condensed", "responsive"))| author | document | bigram |
|---|---|---|
| Einstein, Albert | 3797 | NA |
| Einstein, Albert | 3798 | NA |
| Einstein, Albert | 3799 | NA |
| Einstein, Albert | 3800 | NA |
| Einstein, Albert | 3801 | NA |
| Einstein, Albert | 3802 | relativity the |
| Einstein, Albert | 3802 | the special |
| Einstein, Albert | 3802 | special and |
| Einstein, Albert | 3802 | and general |
| Einstein, Albert | 3802 | general theory |
We can examine the most common bigrams using dplyr’s count():
einstein_bigrams_count <- einstein_bigrams |>
count(bigram, sort = TRUE)kable(head(einstein_bigrams_count, 10)) |>
kable_styling(bootstrap_options = c("striped", "hover", "condensed", "responsive"))| bigram | n |
|---|---|
| NA | 921 |
| of the | 613 |
| to the | 247 |
| in the | 197 |
| of relativity | 164 |
| theory of | 121 |
| with the | 119 |
| on the | 111 |
| that the | 110 |
| of a | 98 |
Now we use tidyr’s separate(), which splits a column into multiple columns based on a delimiter. This lets us separate it into two columns, “word1” and “word2”, at which point we can remove cases where either is a stop-word. This time, we use the stopwords from the package tidyr:
library(tidyr)
# seperate words
bigrams_separated <- einstein_bigrams |>
separate(bigram, c("word1", "word2"), sep = " ")
# filter stop words and NA
bigrams_filtered <- bigrams_separated |>
filter(!word1 %in% stop_words$word) |>
filter(!word2 %in% stop_words$word) |>
filter(!is.na(word1))
# new bigram counts:
bigram_counts <- bigrams_filtered |>
count(word1, word2, sort = TRUE)kable(head(bigram_counts, 10)) |>
kable_styling(bootstrap_options = c("striped", "hover", "condensed", "responsive"))| word1 | word2 | n |
|---|---|---|
| reference | body | 56 |
| gravitational | field | 53 |
| special | theory | 35 |
| ordinate | system | 34 |
| space | time | 27 |
| classical | mechanics | 26 |
| lorentz | transformation | 23 |
| measuring | rods | 22 |
| straight | line | 17 |
| rigid | body | 16 |
This one-bigram-per-row format is helpful for exploratory analyses of the text. As a simple example, we might be interested in the most often mentioned “theory”:
bigram_theory <- bigrams_filtered |>
filter(word2 == "theory") |>
count(word1, sort = TRUE)kable(head(bigram_theory, 7)) |>
kable_styling(bootstrap_options = c("striped", "hover", "condensed", "responsive"))| word1 | n |
|---|---|
| special | 35 |
| lorentz | 4 |
| newton’s | 4 |
| _special | 1 |
| comprehensive | 1 |
| electrodynamic | 1 |
| electromagnetic | 1 |
In other analyses you may be interested in the most common trigrams, which are consecutive sequences of 3 words. We can find this by setting n = 3:
trigram <- books |>
unnest_tokens(trigram, text, token = "ngrams", n = 3) |>
separate(trigram, c("word1", "word2", "word3"), sep = " ") |>
filter(!word1 %in% stop_words$word,
!word2 %in% stop_words$word,
!word3 %in% stop_words$word,
!is.na(word1)) |>
count(word1, word2, word3, sort = TRUE)kable(head(trigram, 7)) |>
kable_styling(bootstrap_options = c("striped", "hover", "condensed", "responsive"))| word1 | word2 | word3 | n |
|---|---|---|---|
| _x_1 | _x_2 | _x_3 | 12 |
| light | _in | vacuo_ | 10 |
| reference | body | _k_ | 10 |
| space | time | continuum | 9 |
| _x_2 | _x_3 | _x_4 | 8 |
| reference | body | _k | 8 |
| disruptive | discharge | coil | 6 |
Network analysis
We may be interested in visualizing all of the relationships among words simultaneously, rather than just the top few at a time. As one common visualization, we can arrange the words into a network, or “graph.” Here we’ll be referring to a “graph” not in the sense of a visualization, but as a combination of connected nodes. A graph can be constructed from a tidy object since it has three variables:
- from: the node an edge is coming from
- to: the node an edge is going towards
- weight: A numeric value associated with each edge
The igraph package has many functions for manipulating and analyzing networks. One way to create an igraph object from tidy data is the graph_from_data_frame() function, which takes a data frame of edges with columns for “from”, “to”, and edge attributes (in this case n):
library(igraph)
# filter for only relatively common combinations
bigram_graph <- bigram_counts |>
filter(n > 5) |>
graph_from_data_frame()We use the ggraph package to convert the igraph object into a ggraph with the ggraph function, after which we add layers to it, much like layers are added in ggplot2. For example, for a basic graph we need to add three layers: nodes, edges, and text:
library(ggraph)
set.seed(123)
ggraph(bigram_graph, layout = "fr") +
geom_edge_link() +
geom_node_point() +
geom_node_text(aes(label = name), vjust = 1, hjust = 1)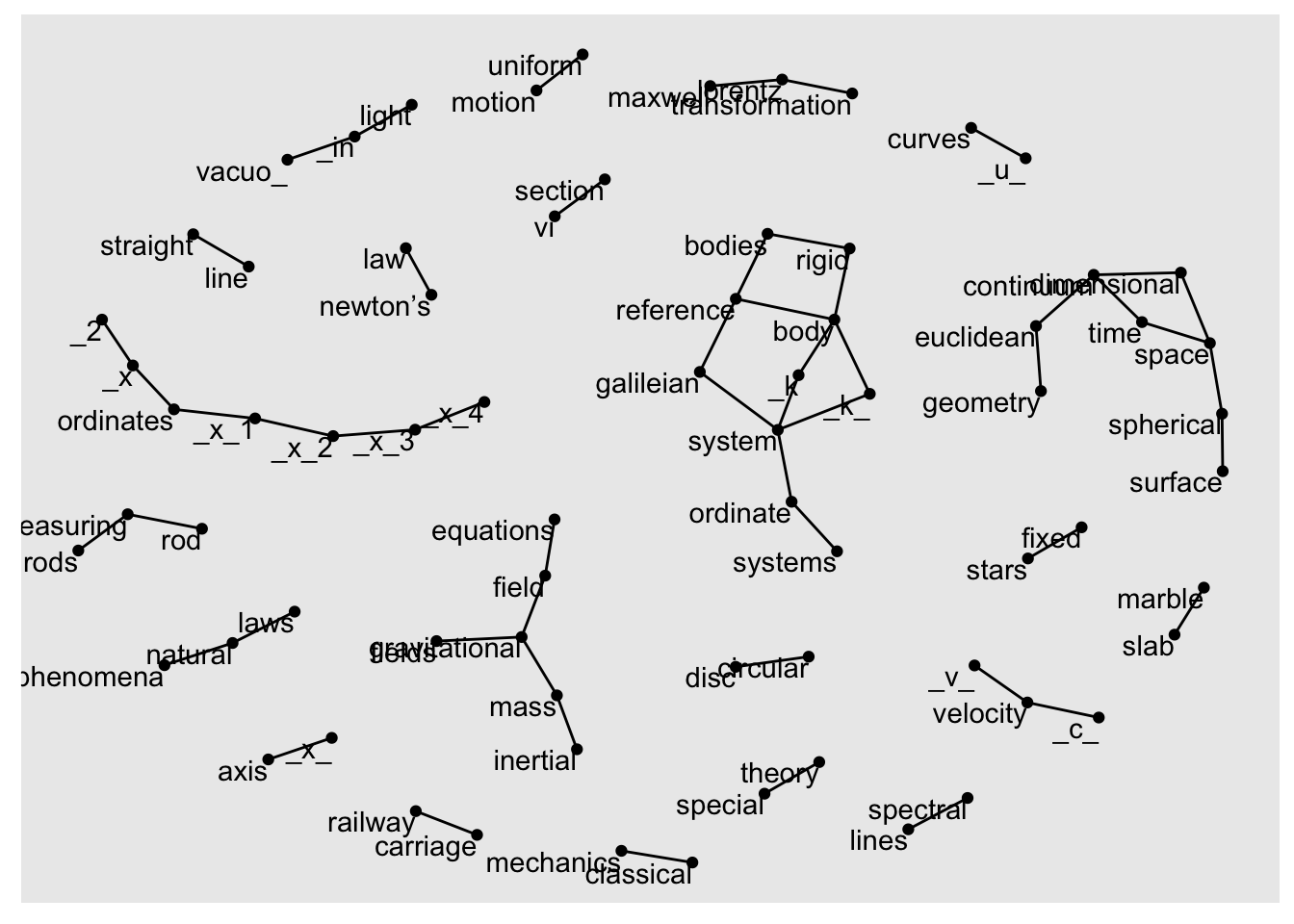
Finally, we will change some settings to obtain to a better looking graph:
We add the
edge_alphaaesthetic to the link layer to make links transparent based on how common or rare the bigram is.We add directionality with an arrow, constructed using
grid::arrow(), including anend_capoption that tells the arrow to end before touching the node.We tinker with the options to the node layer to make the nodes more attractive (larger, blue points).
We add a theme that’s useful for plotting networks,
theme_void().
set.seed(123)
a <- grid::arrow(type = "closed", length = unit(.15, "inches"))
ggraph(bigram_graph, layout = "fr") +
geom_edge_link(aes(edge_alpha = n), show.legend = FALSE,
arrow = a, end_cap = circle(.07, 'inches')) +
geom_node_point(color = "lightblue", size = 5) +
geom_node_text(aes(label = name), vjust = 1, hjust = 1) +
theme_void()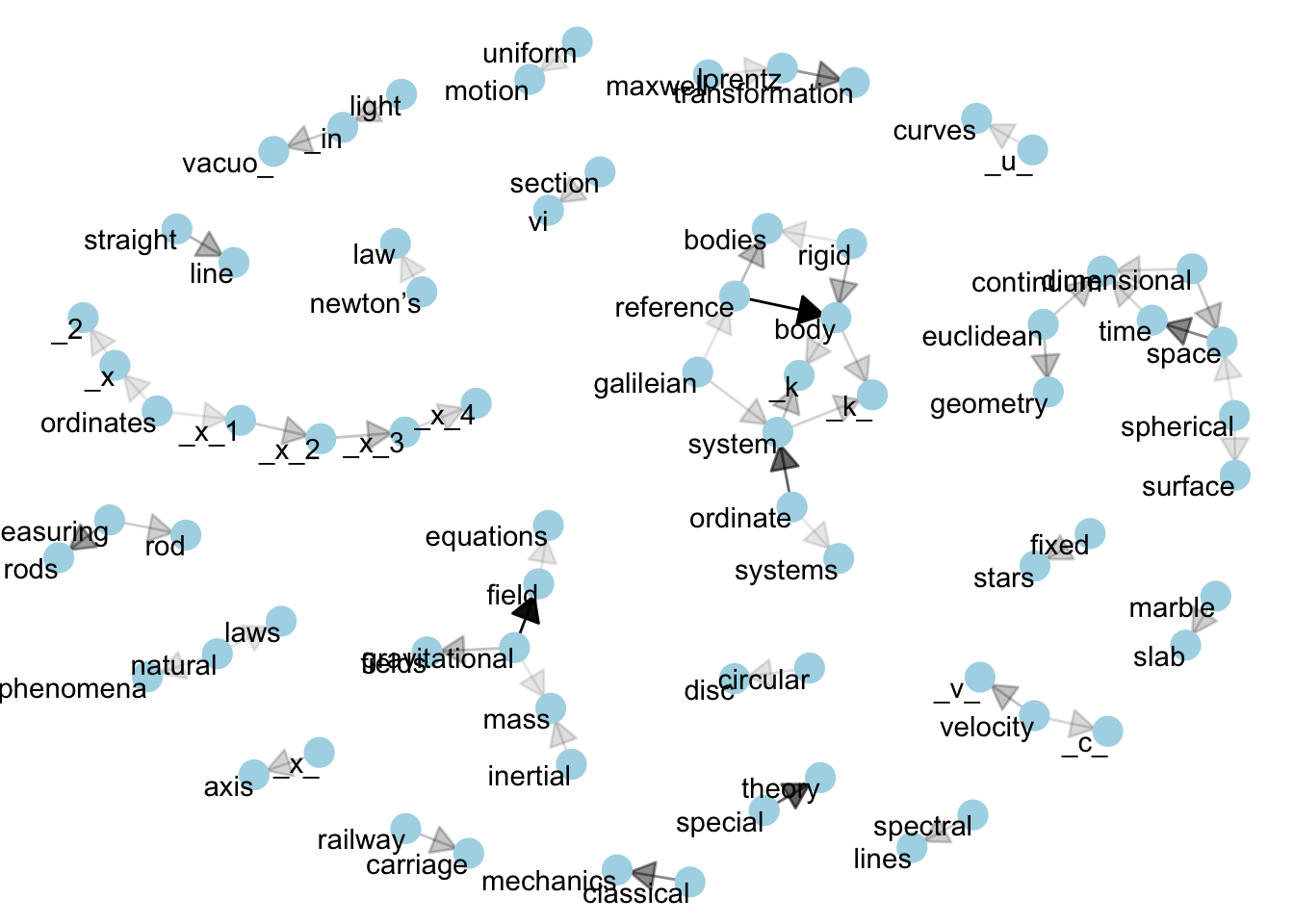
Classification with logistic regression
In the first part we will build a statistical learning model. In the second part we will want to test it and assess its quality. Without dividing the dataset we would test the model on the data which the algorithm have already seen, which is why we start by splitting the data.
Train test split
Let’s go back to the original books dataset (not the tidy_books dataset) because the lines of text are our individual observations.
We could use functions from the rsample package to generate resampled datasets, but the specific modeling approach we’re going to use will do that for us so we only need a simple train/test split.
library(rsample)
books_split <- books |>
select(document) |>
initial_split(prop = 3/4)
train_data <- training(books_split)
test_data <- testing(books_split)Notice that we just select specific text rows (column document) for training and others for our test data (we set the proportion of data to be retained for modeling/analysis to 3/4) without selecting the actual text lines at this point.
Training data (sparse matrix)
Now we want to transform our training data from a tidy data structure to a “sparse matrix” (these objects can be treated as though they were matrices, for example accessing particular rows and columns, but are stored in a more efficient format) to use for our classification algorithm.
sparse_words <- tidy_books |>
count(document, word) |>
inner_join(train_data, by = "document") |>
cast_sparse(document, word, n)dim(sparse_words)[1] 4769 893We have over 4,700 training observations and almost 900 features. Text feature space handled in this way is very high dimensional, so we need to take that into account when considering our modeling approach.
One reason this overall approach is flexible is that you could at this point cbind() other columns, such as non-text numeric data, onto this sparse matrix. Then you can use this combination of text and non-text data as your predictors in the classifiaction algorithm, and the regularized regression algorithm we are going to use will find which are important for your problem space.
Response variable
We also need to build a tibble with a response variable to associate each of the rownames() of the sparse matrix with an author, to use as the quantity we will predict in the model.
word_rownames <- as.integer(rownames(sparse_words))books_joined <- tibble(document = word_rownames) |>
left_join(books |>
select(document, author))kable(head(books_joined, 7)) |>
kable_styling(bootstrap_options = "striped", "hover", "condensed", "responsive", full_width = F, position = "center")| document | author |
|---|---|
| 1 | Tesla, Nikola |
| 3 | Tesla, Nikola |
| 5 | Tesla, Nikola |
| 11 | Tesla, Nikola |
| 21 | Tesla, Nikola |
| 24 | Tesla, Nikola |
| 25 | Tesla, Nikola |
Logistic regression model
Now it’s time to train our classification model. Let’s use the glmnet package to fit a logistic regression model with lasso (least absolute shrinkage and selection operator; also Lasso or LASSO) regularization. This regression analysis method performs both variable selection and regularization in order to enhance the prediction accuracy and interpretability of the statistical model it produces.
Glmnet is a package that fits lasso models via penalized maximum likelihood. We do not cover the method and glmnet package in detail at this point, but if you want to learn more about glmnet and lasso regression, review the following resources:
The package is very useful for text classification because the variable selection that lasso regularization performs can tell you which words are important for your prediction problem. The glmnet package also supports parallel processing, so we can train on multiple cores with cross-validation on the training set using cv.glmnet().
library(glmnet)
is_einstein <- books_joined$author == "Einstein, Albert"
model <- cv.glmnet(sparse_words,
is_einstein,
family = "binomial",
parallel = TRUE,
keep = TRUE)Let’s use the package broom (the broom package takes the messy output of built-in functions in R, such as lm, nls, or t.test, and turns them into tidy data frames) to check out the coefficients of the model, for the largest value of lambda with error within 1 standard error of the minimum (lambda.1se).
library(broom)
coefs <- model$glmnet.fit |>
tidy() |>
filter(lambda == model$lambda.1se)Which coefficents are the largest in size, in each direction:
library(forcats)
coefs |>
group_by(estimate > 0) |>
top_n(10, abs(estimate)) |>
ungroup() |>
ggplot(aes(fct_reorder(term, estimate), estimate, fill = estimate > 0)) +
geom_col(alpha = 0.8, show.legend = FALSE) +
coord_flip() +
labs(
x = NULL,
title = "Coefficients that increase/decrease probability the most",
subtitle = "A document mentioning lecture or probably is unlikely to be written by Albert Einstein"
) +
theme_classic(base_size = 12) +
theme(plot.title = element_text(lineheight=.8, face="bold")) +
scale_fill_brewer() 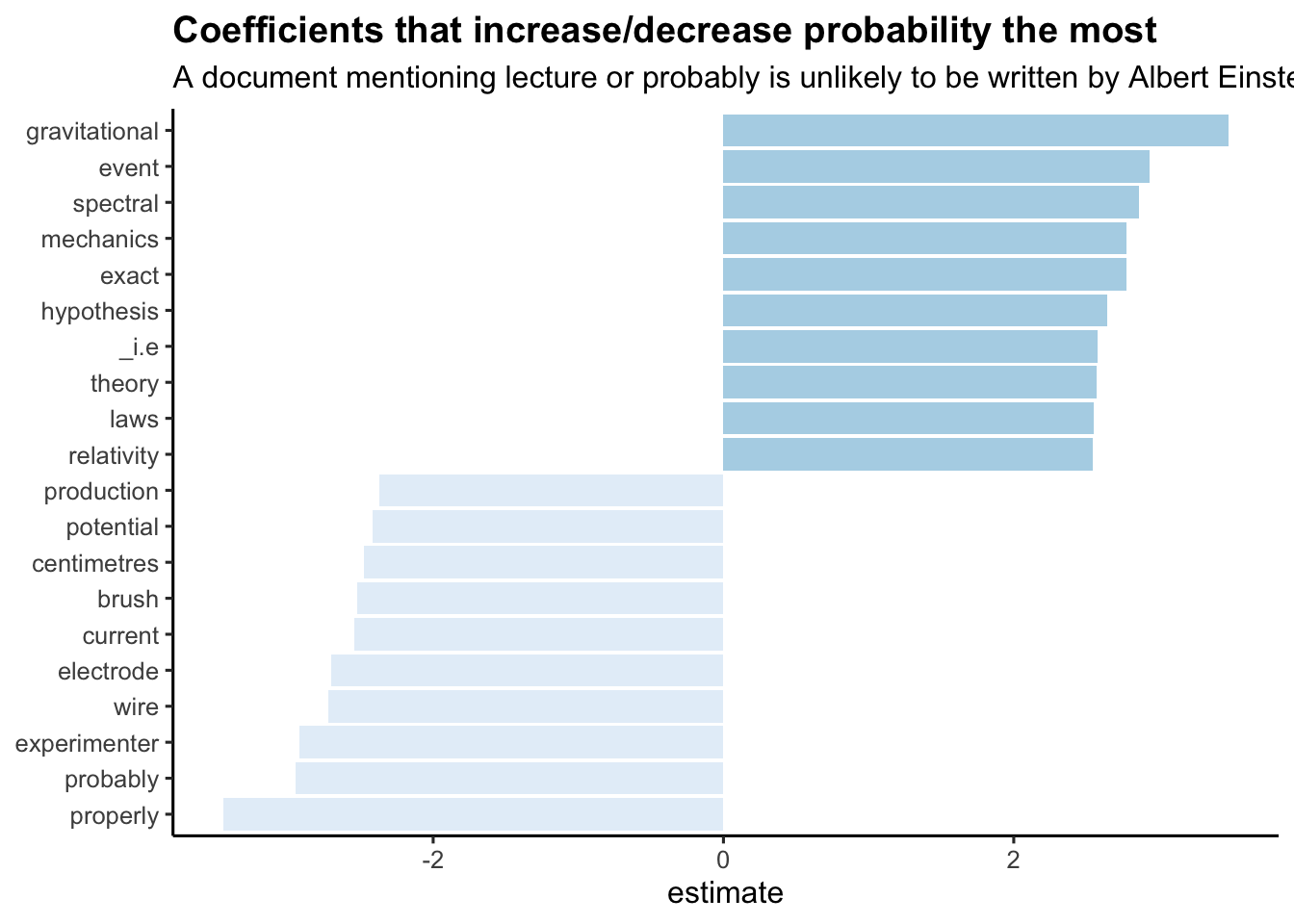
Model evaluation with test data
Now we want to evaluate how well this model is doing using the test data that we held out and did not use for training the model. Let’s create a dataframe that tells us, for each document in the test set, the probability of being written by Albert Einstein.
intercept <- coefs |>
filter(term == "(Intercept)") |>
pull(estimate)
classifications <- tidy_books |>
inner_join(test_data) |>
inner_join(coefs, by = c("word" = "term")) |>
group_by(document) |>
summarize(score = sum(estimate)) |>
mutate(probability = plogis(intercept + score))kable(head(classifications, 7)) |>
kable_styling(bootstrap_options = "striped", "hover", "condensed", "responsive", full_width = F, position = "center")| document | score | probability |
|---|---|---|
| 7 | -1.6569483 | 0.1715378 |
| 9 | -0.5226801 | 0.3916220 |
| 27 | -1.2047108 | 0.2455423 |
| 32 | -1.0465089 | 0.2760125 |
| 36 | -0.5824899 | 0.3774680 |
| 38 | -0.1416163 | 0.4851455 |
| 40 | -4.7306180 | 0.0094857 |
Now let’s use the yardstick package (yardstick is a package to estimate how well models are working using tidy data principles) to calculate some model performance metrics. For example, what does the ROC curve (receiver operating characteristic curve - a graph showing the performance of a classification model at all classification thresholds) look like:
library(yardstick)
comment_classes <- classifications |>
left_join(books |>
select(author, document), by = "document") |>
mutate(author = as.factor(author))
comment_classes# A tibble: 1,553 × 4
document score probability author
<int> <dbl> <dbl> <fct>
1 7 -1.66 0.172 Tesla, Nikola
2 9 -0.523 0.392 Tesla, Nikola
3 27 -1.20 0.246 Tesla, Nikola
4 32 -1.05 0.276 Tesla, Nikola
5 36 -0.582 0.377 Tesla, Nikola
6 38 -0.142 0.485 Tesla, Nikola
7 40 -4.73 0.00949 Tesla, Nikola
8 41 -3.18 0.0434 Tesla, Nikola
9 42 -0.209 0.468 Tesla, Nikola
10 46 -0.433 0.413 Tesla, Nikola
# ℹ 1,543 more rowsroc <- comment_classes |>
roc_curve(author, probability)
roc |>
ggplot(aes(x = 1 - specificity, y = sensitivity)) +
geom_line(
color = "midnightblue",
size = 1.5
) +
geom_abline(
lty = 2, alpha = 0.5,
color = "gray50",
size = 1.2
) +
labs(
title = "ROC curve for text classification using regularized regression",
subtitle = "Predicting whether text was written by Albert Einstein or Nikola Tesla"
) +
theme_classic(base_size = 12) +
theme(plot.title = element_text(lineheight=.8, face="bold"))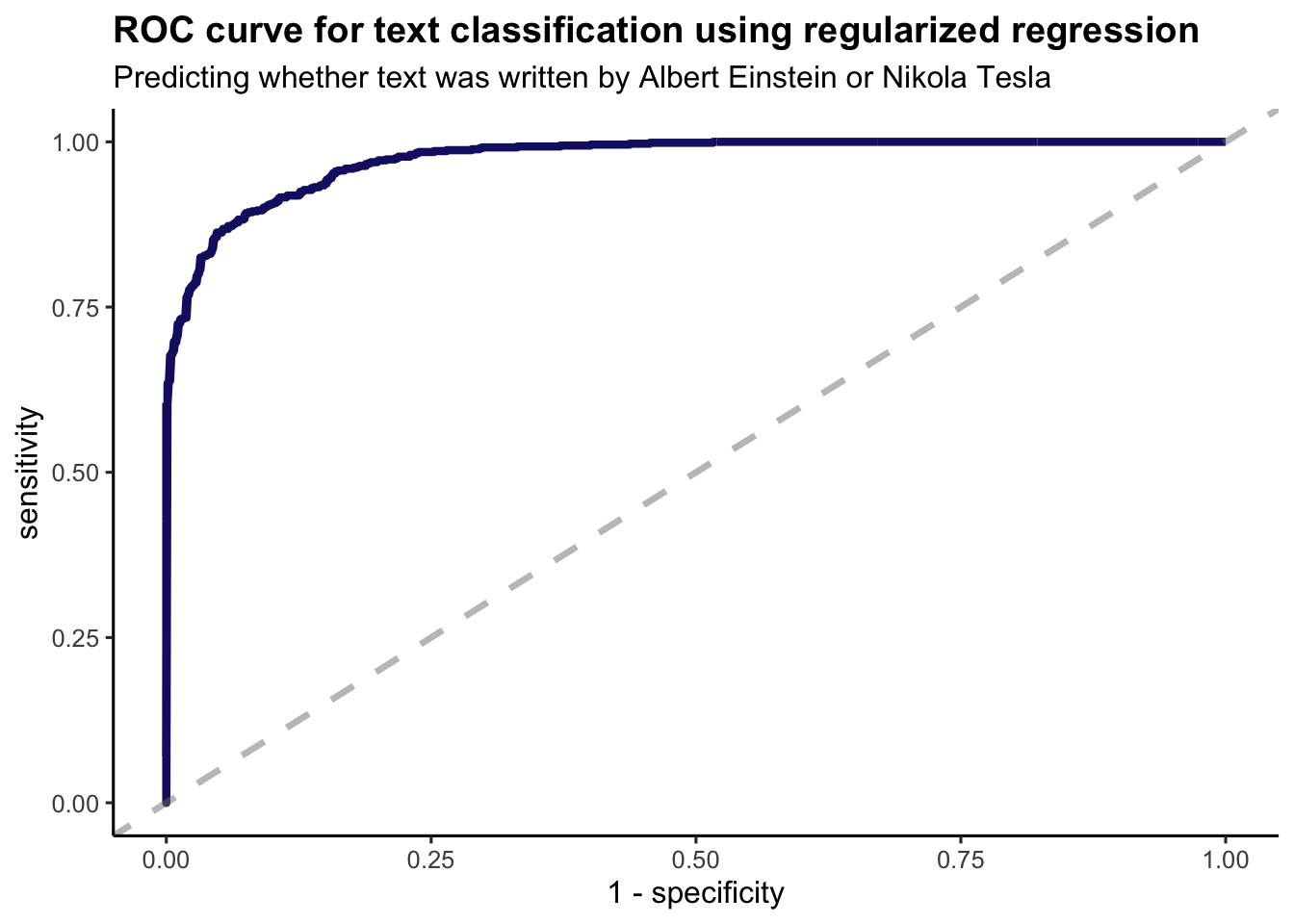
Let’s obtain the accuracy (AUC - the fraction of predictions that a classification model got right) on the test data:
auc <- comment_classes |>
roc_auc(author, probability)kable(auc) |>
kable_styling(bootstrap_options = "striped", "hover", "condensed", "responsive", full_width = F, position = "center")| .metric | .estimator | .estimate |
|---|---|---|
| roc_auc | binary | 0.9741431 |
Next we turn to the confusion matrix. Let’s make the following definitions:
- “Einstein, Albert” is a positive class.
- “Tesla, Nikola” is a negative class.
| True Positive (TP): | False Positive (FP): |
|---|---|
| Reality: Text is from Einstein | Reality: Text is from Tesla |
| Model: Text is from Einstein | Model: Text is from Einstein |
| False Negative (FN): | True Negative (TN): |
|---|---|
| Reality: Text is from Einstein | Reality: Text is from Tesla |
| Model: Text is from Tesla | Model: Text is from Tesla |
We can summarize our “einstein-text-prediction” model using a 2x2 confusion matrix that depicts all four possible outcomes:
A true positive is an outcome where the model correctly predicts the positive class (Einstein). Similarly, a true negative is an outcome where the model correctly predicts the negative class (Tesla).
A false positive is an outcome where the model incorrectly predicts the positive class. And a false negative is an outcome where the model incorrectly predicts the negative class.
Let’s use a probability of 0.5 as our threshold. That means all model predictions with a probability greater than 50% get labeld as beeing text from Einstein:
comment_classes |>
mutate(prediction = case_when(
probability > 0.5 ~ "Einstein, Albert",
TRUE ~ "Tesla, Nikola"),
prediction = as.factor(prediction)) |>
conf_mat(author, prediction) Truth
Prediction Einstein, Albert Tesla, Nikola
Einstein, Albert 646 82
Tesla, Nikola 68 757Let’s take a closer look at these misclassifications: false negatives (FN) and false positives (FP). Which documents here were incorrectly predicted to be written by Albert Einstein, at the extreme probability end of greater than 80% (false positive)?
FP<- comment_classes |>
filter(probability > .8,
author == "Tesla, Nikola") |>
sample_n(10) |>
inner_join(books |>
select(document, text)) |>
select(probability, text)kable(FP) |>
kable_styling(bootstrap_options = "striped", "hover", "condensed", "responsive", full_width = F, position = "center")| probability | text |
|---|---|
| 0.8592571 | From experiences of this kind I am led to infer that, in order to be |
| 0.9115352 | already described, except with the view of completing, or more clearly |
| 0.8991634 | there is any motion which is measurable going on in the space, such a |
| 0.8161307 | [Transcriber's note: Corrected the following typesetting errors: |
| 0.8024522 | principle of the vacuum pump of the future. For the present, we must |
| 0.8213111 | shown by the following experiment: |
| 0.8963556 | brilliancy. Next, suppose we diminish to any degree we choose the |
| 0.8449774 | covered with a milky film, which is separated by a dark space from the |
| 0.8447254 | medium surely must exist, and I am convinced that, for instance, even |
| 0.8027681 | velocity--the energy associated with the moving body--is another, and |
These documents were incorrectly predicted to be written by Albert Einstein. However, they were written by Nikola Tesla.
Finally, let’s take a look at the texts which are from Albert Einstein that the model did not correctly identify (false negative):
FN <- comment_classes |>
filter(probability < .3,
author == "Einstein, Albert") |>
sample_n(10) |>
inner_join(books |>
select(document, text)) |>
select(probability, text)kable(FN) |>
kable_styling(bootstrap_options = "striped", "hover", "condensed", "responsive", full_width = F, position = "center")| probability | text |
|---|---|
| 0.2932465 | another, shall indicate position and time directly. Such was the |
| 0.2447074 | This conception is in itself not very satisfactory. It is still less |
| 0.1485998 | was necessary to surmount a serious difficulty, and as this lies deep |
| 0.2958725 | potential φ, hence the result we have obtained will hold quite |
| 0.2572766 | [20] Mathematicians have been confronted with our problem in the |
| 0.2032739 | any doubt to arise as to the prime importance of the Galileian |
| 0.0453919 | bring some one a few happy hours of suggestive thought! |
| 0.1163048 | ideas among themselves. |
| 0.2196137 | connection in which they actually originated. In the interest of |
| 0.2389984 | strings to the floor, otherwise the slightest impact against the floor |
We can conclude that the model did a very good job in predicting the authors of the texts. Furthermore, the texts of the misclassifications are quite short and we can imagine, that even a human reader who is familiar with the work of Einstein and Tesla would have difficulties to classify them correctly.