import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow.keras import layers
tf.__version__This tutorial is mainly based on the Keras tutorial “Structured data classification from scratch” by François Chollet and “Classify structured data using Keras preprocessing layers” by TensorFlow.
This tutorial demonstrates how to do structured binary classification with Keras (Version 3), starting from a raw CSV file.
Setup
First of all, we use Anaconda to create a new environment called keras. Open your terminal (macOS) or your Anaconda Command Prompt (Windows) and enter:
conda create -n keras python=3.11 pipActivate the environment:
conda activate kerasLet’s install some packages.
pip install ipykernel jupyter pandas numpy tensorflow keras pydot If you are using Visual Studio Code, you first need to restart Vode before you can slect the new environment in your kernel picker.
You also need to install graphviz (see instructions at https://graphviz.gitlab.io/download/) to plot the model architecture.
Data
- We use the features below to predict whether a patient has a heart disease (
Target).
| featureumn | Description | Feature Type |
|---|---|---|
| Age | Age in years | Numerical |
| Sex | (1 = male; 0 = female) | Categorical |
| CP | Chest pain type (0, 1, 2, 3, 4) | Categorical |
| Trestbpd | Resting blood pressure (in mm Hg on admission) | Numerical |
| Chol | Serum cholesterol in mg/dl | Numerical |
| FBS | fasting blood sugar in 120 mg/dl (1 = true; 0 = false) | Categorical |
| RestECG | Resting electrocardiogram results (0, 1, 2) | Categorical |
| Thalach | Maximum heart rate achieved | Numerical |
| Exang | Exercise induced angina (1 = yes; 0 = no) | Categorical |
| Oldpeak | ST depression induced by exercise relative to rest | Numerical |
| Slope | Slope of the peak exercise ST segment | Numerical |
| CA | Number of major vessels (0-3) featureored by fluoroscopy | Both numerical & categorical |
| Thal | normal; fixed defect; reversible defect | Categorical (string) |
| Target | Diagnosis of heart disease (1 = true; 0 = false) | Target |
Data import
- Let’s download the data and load it into a Pandas dataframe:
file_url = "http://storage.googleapis.com/download.tensorflow.org/data/heart.csv"
df = pd.read_csv(file_url)df.head()df.info()Define label
- Define outcome variable as
y_label
y_label = 'target'Data format
First, we make some changes to our data
Due to computational performance reasons we change:
int64toint32float64tofloat32
# Make a dictionary with int64 featureumns as keys and np.int32 as values
int_32 = dict.fromkeys(df.select_dtypes(np.int64).columns, np.int32)
# Change all columns from dictionary
df = df.astype(int_32)
# Make a dictionary with float64 columns as keys and np.float32 as values
float_32 = dict.fromkeys(df.select_dtypes(np.float64).columns, np.float32)
df = df.astype(float_32)int_32- Next, we take care of our categorical data:
# Convert to string
df['thal'] = df['thal'].astype("string")# Convert to categorical
# make a list of all categorical variables
cat_convert = ['sex', 'cp', 'fbs', 'restecg', 'exang', 'ca']
# convert variables
for i in cat_convert:
df[i] = df[i].astype("category")- Finally, we make lists of feature variables for later data preprocessing steps
- Since we don’t want to include our label in our data preprocessing steps, we make sure to exclude it
# Make list of all numerical data (except label)
list_num = df.drop(columns=[y_label]).select_dtypes(include=[np.number]).columns.tolist()
# Make list of all categorical data which is stored as integers (except label)
list_cat_int = df.drop(columns=[y_label]).select_dtypes(include=['category']).columns.tolist()
# Make list of all categorical data which is stored as string (except label)
list_cat_string = df.drop(columns=[y_label]).select_dtypes(include=['string']).columns.tolist()df.info()Data splitting
- Let’s split the data into a training and validation set
# Make validation data
df_val = df.sample(frac=0.2, random_state=1337)
# Create training data
df_train = df.drop(df_val.index)# Save training data
df_train.to_csv("df_train.csv", index=False)print(
"Using %d samples for training and %d for validation"
% (len(df_train), len(df_val))
)Transform to Tensors
Let’s generate
tf.data.Datasetobjects for our training and validation dataframesThe following utility function converts each training and validation set into a tf.data.Dataset, then shuffles and batches the data.
# Define a function to create our tensors
def dataframe_to_dataset(dataframe, shuffle=True, batch_size=32):
df = dataframe.copy()
labels = df.pop(y_label)
ds = tf.data.Dataset.from_tensor_slices((dict(df), labels))
if shuffle:
ds = ds.shuffle(buffer_size=len(dataframe))
ds = ds.batch(batch_size)
df = ds.prefetch(batch_size)
return ds- Next, we use our function to create batches of tensors with size 32
batch_size = 32
ds_train = dataframe_to_dataset(df_train, shuffle=True, batch_size=batch_size)
ds_val = dataframe_to_dataset(df_val, shuffle=True, batch_size=batch_size)Feature preprocessing
Next, we define utility functions to do the feature preprocessing operations.
In this tutorial, you will use the following preprocessing layers to demonstrate how to perform preprocessing, structured data encoding, and feature engineering:
tf.keras.layers.Normalization: Performs feature-wise normalization of input features.tf.keras.layers.CategoryEncoding: Turns integer categorical features into one-hot, multi-hot, or tf-idf dense representations.tf.keras.layers.StringLookup: Turns string categorical values into integer indices.tf.keras.layers.IntegerLookup: Turns integer categorical values into integer indices.
Numerical preprocessing function
- Define a new utility function that returns a layer which applies feature-wise normalization to numerical features using that Keras preprocessing layer:
# Define numerical preprocessing function
def get_normalization_layer(name, dataset):
# Create a Normalization layer for our feature
normalizer = layers.Normalization(axis=None)
# Prepare a dataset that only yields our feature
feature_ds = dataset.map(lambda x, y: x[name])
# Learn the statistics of the data
normalizer.adapt(feature_ds)
# Normalize the input feature
return normalizerCategorical preprocessing functions
Define another new utility function that returns a layer which maps values from a vocabulary to integer indices and multi-hot encodes the features using the preprocessing layers:
layers.StringLookuplayers.IntegerLookuplayersCategoryEncoding
If the vocabulary is capped in size (
max_tokens), the most frequent tokens will be used to create the vocabulary and all others will be treated as out-of-vocabulary (OOV).
def get_category_encoding_layer(name, dataset, dtype, max_tokens=None):
# Create a layer that turns strings into integer indices.
if dtype == 'string':
index = layers.StringLookup(max_tokens=max_tokens)
# Otherwise, create a layer that turns integer values into integer indices.
else:
index = layers.IntegerLookup(max_tokens=max_tokens)
# Prepare a `tf.data.Dataset` that only yields the feature.
feature_ds = dataset.map(lambda x, y: x[name])
# Learn the set of possible values and assign them a fixed integer index.
index.adapt(feature_ds)
# Encode the integer indices.
encoder = layers.CategoryEncoding(num_tokens=index.vocabulary_size())
# Apply multi-hot encoding to the indices. The lambda function captures the
# layer, so you can use them, or include them in the Keras Functional model later.
return lambda feature: encoder(index(feature))Data preprocessing
Next, we will:
Apply the preprocessing utility functions defined earlier on our numerical and categorical features and store it into a list called
encoded_featuresWe also add all of our features to a list called
all_inputs.Let’s start by preparing two empty lists:
all_inputs = []
encoded_features = []Numerical preprocessing
For every feature:
create a
tf.keras.Inputcalled numeric_featureNormalize the numerical feature
Add the feature name to the list
all_inputsAdd the encoded numeric feature ro our list
encoded_features:
# Numerical features
for feature in list_num:
numeric_feature = tf.keras.Input(shape=(1,), name=feature)
normalization_layer = get_normalization_layer(feature, ds_train)
encoded_numeric_feature = normalization_layer(numeric_feature)
all_inputs.append(numeric_feature)
encoded_features.append(encoded_numeric_feature)Categorical preprocessing
- Turn the integer categorical values from the dataset into integer indices, perform multi-hot encoding and add the resulting feature inputs to encoded_feature
for feature in list_cat_int:
categorical_feature = tf.keras.Input(shape=(1,), name=feature, dtype='int32')
encoding_layer = get_category_encoding_layer(name=feature,
dataset=ds_train,
dtype='int32',
max_tokens=5)
encoded_categorical_feature = encoding_layer(categorical_feature)
all_inputs.append(categorical_feature)
encoded_features.append(encoded_categorical_feature)for feature in list_cat_string:
categorical_feature = tf.keras.Input(shape=(1,), name=feature, dtype='string')
encoding_layer = get_category_encoding_layer(name=feature,
dataset=ds_train,
dtype='string',
max_tokens=5)
encoded_categorical_feature = encoding_layer(categorical_feature)
all_inputs.append(categorical_feature)
encoded_features.append(encoded_categorical_feature)Model
Now we can build the model using the Keras Functional API:
Merge the list of feature inputs (
encoded_features) into one vector via concatenation withlayers.concatenate.We use 32 number of units in the first layer
We use layers.Dropout() to prevent overvitting
Our output layer has 1 output (since the classification task is binary)
tf.keras.Model groups layers into an object with training and inference features.
# Input
all_features = layers.concatenate(encoded_features)
# First layer
x = layers.Dense(32, activation="relu")(all_features)
# Dropout to prevent overvitting
x = layers.Dropout(0.5)(x)
# Output layer
output = layers.Dense(1, activation="sigmoid")(x)
# Group all layers
model = tf.keras.Model(all_inputs, output)- Configure the model with Keras Model.compile:
model.compile(optimizer="adam",
loss ="binary_crossentropy",
metrics=["accuracy"])- Let’s visualize our connectivity graph:
# `rankdir='LR'` is to make the graph horizontal.
tf.keras.utils.plot_model(model, show_shapes=True, rankdir="LR")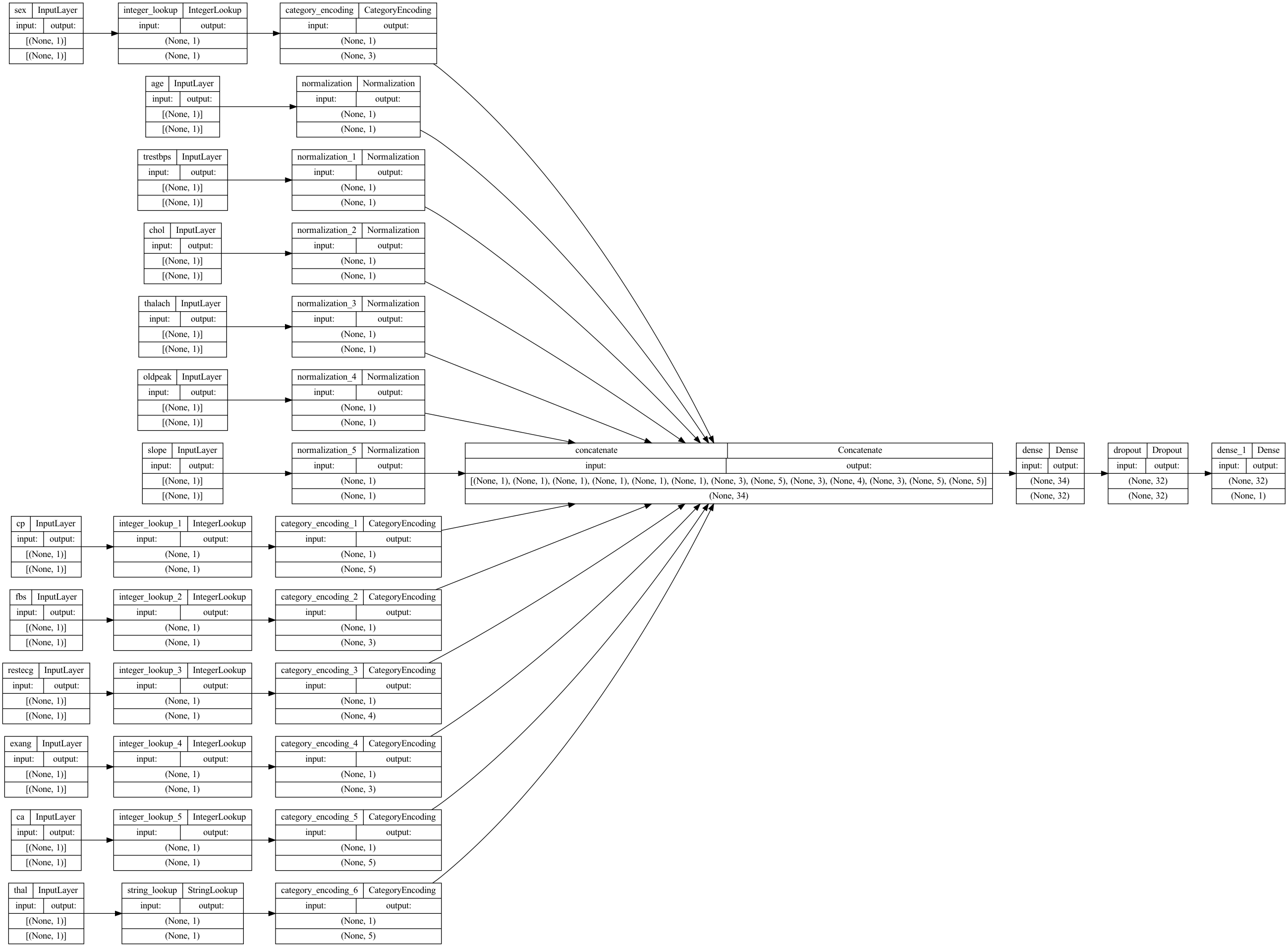
Training
- Next, train and test the model:
%%time
model.fit(ds_train, epochs=10, validation_data=ds_val)- We quickly get to arounf 80% validation accuracy.
loss, accuracy = model.evaluate(ds_val)
print("Accuracy", round(accuracy, 2))Perform inference
The model you have developed can now classify a row from a CSV file directly after you’ve included the preprocessing layers inside the model itself.
Next, we demonstrate the process.
First, save the heart diseases classification model
model.save('my_hd_classifier')- Load the model (we call it
reloaded_model):
reloaded_model = tf.keras.models.load_model('my_hd_classifier')To get a prediction for a new sample, you can simply call the Keras
Model.predictmethod.There are just two things you need to do:
Wrap scalars into a list so as to have a batch dimension (Models only process batches of data, not single samples).
Call
tf.convert_to_tensoron each feature.
sample = {
"age": 60,
"sex": 1,
"cp": 1,
"trestbps": 145,
"chol": 233,
"fbs": 1,
"restecg": 2,
"thalach": 150,
"exang": 0,
"oldpeak": 2.3,
"slope": 3,
"ca": 0,
"thal": "fixed",
}input_dict = {name: tf.convert_to_tensor([value]) for name, value in sample.items()}predictions = reloaded_model.predict(input_dict)print(
"This particular patient had a %.1f percent probability "
"of having a heart disease, as evaluated by our model." % (100 * predictions[0][0],)
)Next steps
To learn more about classifying structured data, try working with other datasets. Below are some suggestions for datasets:
TensorFlow Datasets: MovieLens: A set of movie ratings from a movie recommendation service.
TensorFlow Datasets: Wine Quality: Two datasets related to red and white variants of the Portuguese “Vinho Verde” wine. You can also find the Red Wine Quality dataset on Kaggle.
Kaggle: arXiv Dataset: A corpus of 1.7 million scholarly articles from arXiv, covering physics, computer science, math, statistics, electrical engineering, quantitative biology, and economics.